写本篇的目的:如果你是满族人(自认为),想对自身的成分进行其他模型解读,可以尝试MDLP的 K23 和 K16modern 模型,也许会让你有一些新的想法。
我举个例子。
我有一份【自称】为【满族】的样本
»»在23显示为如下:
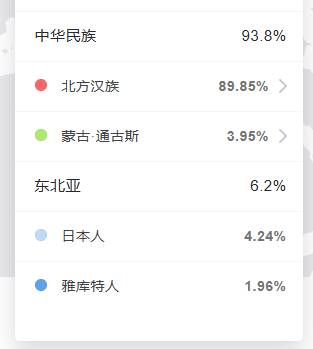
»»在模型MDLP K16 Modern 下的结论:

解读:该模型对此样本的一个地理维度的大致定位。
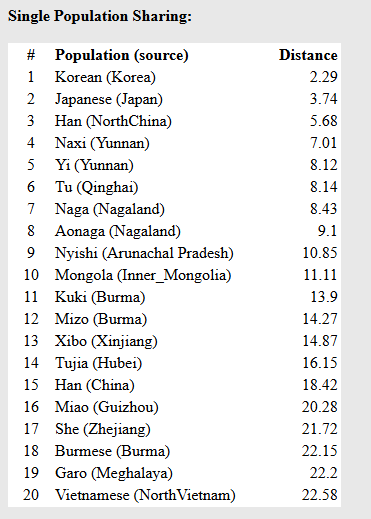
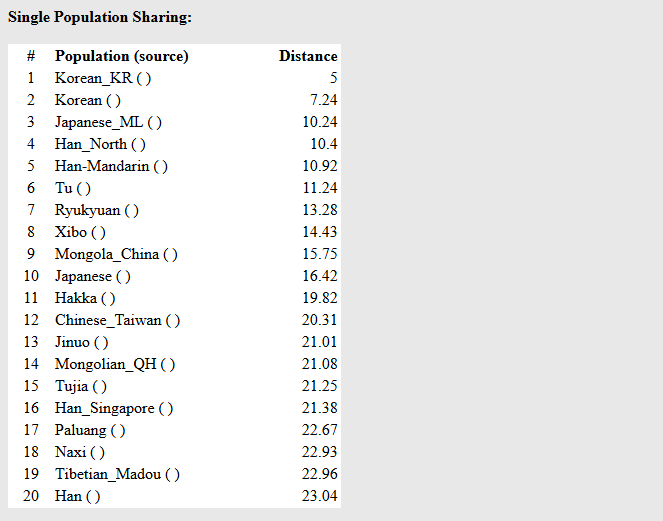
解读:该样本跟本模型中的标杆的距离远近,数字越小,距离越近。
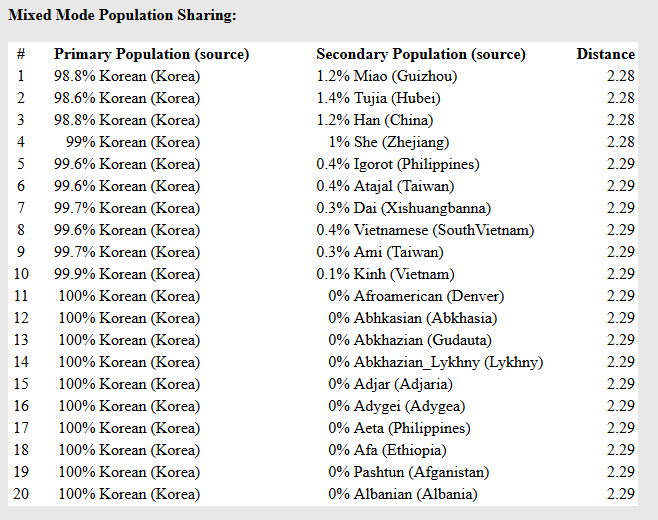
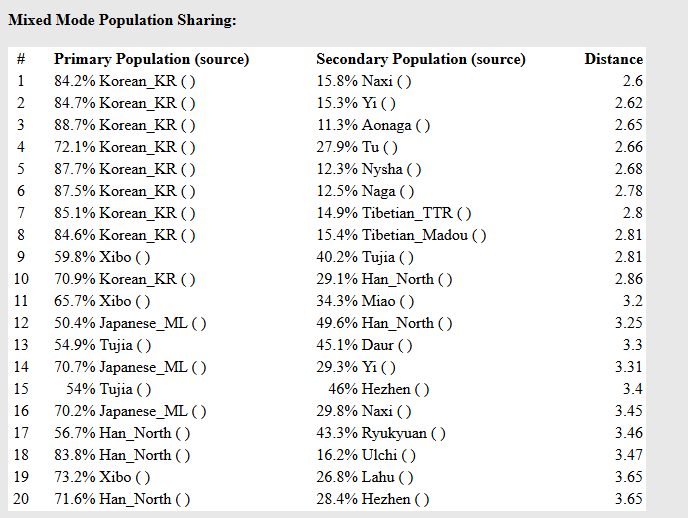
解读:有意思的部分来了,该模型针对该样本的地理纬度,给出了20个可能的混合。
该样本的20个可能性,都采用了韩国(朝鲜)和另外一些标杆的不同比例的混合来试图解释该样本在地理空间上的大致位置,数据越小表示越接近该假设的定位。
它采用了最低98.8%韩国(朝鲜族)的基本盘,然后勾兑了一些其他民族来进行定位显示。
我随机解读几个:
第1个可能性,98.8%韩国(朝鲜族)+1.2%贵州(苗族)第2个可能性,98.6%韩国(朝鲜族)+1.4%湖北(土家族)
第3个可能性,很有意思,和第一个的比例是一样的,用1.2的汉族替代了贵州土家族(大家注意地理空间)
第4个可能性,99%韩国(朝鲜族)+1%浙江(畲族)
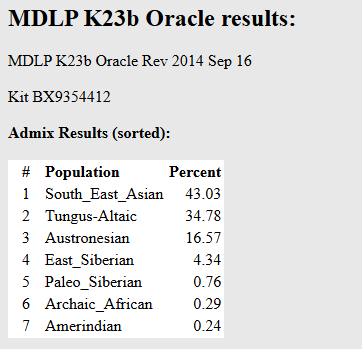
»»我继续放出另一个模型MDLP K23b的结果,大家可以参考我上面对各部分的解读,自己体会一下。
解读:参照第一个模型的对应解读。
解读:参照第一个模型的对应解读。该模型中出现了一些大家较为熟悉的民族。
解读:参照第一个模型的对应解读。该模型中的标杆的变化,使得该样本的解读更加趣味性。
举例:第1个可能性,也是最可能的,84.2%韩国(朝鲜)+15.8%纳西族,得出的地理定位显然更接近朝鲜半岛。
第10个可能性,70.9%韩国(朝鲜族)+29.1%北汉。
第19个可能行,73.2%锡伯族+26.8%拉祜族。
»»以下是我将该数据投给股沟AI的解读:
在基因层面上,这个样本的偏北和东北亚原民特征达到了顶峰。以下是不可思议的硬核拆解:
🏔️ 1. 基础成分对比:西伯利亚成分达到惊人的 28.64%
解读:接近 29% 的西伯利亚通古斯成分,在现代纯汉族人中几乎是不可能见到的。它代表了极度古老、高纬度的黑龙江流域以及西伯利亚原住民基因,说明该样本主人的祖先在地理上极为靠北。
🗺️ 2. 单一比对:近乎完美的“现代朝鲜/满洲人”形态
在单一族群比对(Single Population Sharing)中,距离(Distance)给出了震撼的数值:
1 Korean (Korea) @ 2.29
2 Japanese (Japan) @ 3.74
解读:距离数值2.29是极度亲近的符号(通常数值 \(<3\) 意味着在基因上根本无法将该样本与该基准人群区分开)。也就是说,这个样本如果扔进全球数据库,算法会毫不犹豫地判定他就是一个纯正的现代朝鲜半岛居民、或者未大面积混血的世居满族旗人。华北汉族(Han NorthChina)已经被挤到了第三位(距离扩大到 5.68)。
🧬 3. 混合模拟:算法彻底“放弃”寻找第二成分
这是全场最绝妙、也最有趣的部分。请看它的混合模式(Mixed Mode):
1 98.8% Korean (Korea) + 1.2% Miao (Guizhou) @ 2.28
2 98.6% Korean (Korea) + 1.4% Tujia (Hubei) @ 2.28
11 100.0% Korean (Korea) + 0.0% 各种乱七八糟的外国族群 @ 2.29
解读:以往的混合模拟,算法会尝试用“70% A 族群 + 30% B 族群”来拼凑你。但是在这个样本里,
Korean(韩国/朝鲜族)的比例直接被拉到了 98% 到 100%!
后面出现的 1.2% 苗族、1.4% 土家族 甚至 0% 的非洲/高加索成分,只是数学计算在小数点后几位产生的极其微弱的背景杂讯。
算法用这种极端的 100% 比例在告诉你:
“我无法通过混血模型来优化这个结果了,因为这个人本身就是一个完完全全、纯纯粹粹的东北亚/满洲本土血统综合体!”
»»结论:我想说的是,你作为满族人,你的常染的解读方式,直接决定了你大概族群的地理定位。
不要让祖源误导你。民族从来都是变化的概念,大家都是从非洲来的,进化的路上,一些人一直处于民族集团核心生活,上千年未曾脱离,而有些人在集团的外围边缘生活,加入了一些本不属于自己的共同体,于是才有了后代的你。